近日,前 OpenAI 科学家 Andrej Karpathy 在 GitHub 上分享了一篇题为 LLM Wiki 的短文,提出了一个极具启发性的个人知识库构建新范式。
对于习惯了 ChatGPT 文件上传和主流 RAG(检索增强生成)系统的我们来说,这篇短文犹如醍醐灌顶:它重新定义了人类与大模型协作管理知识的方式。
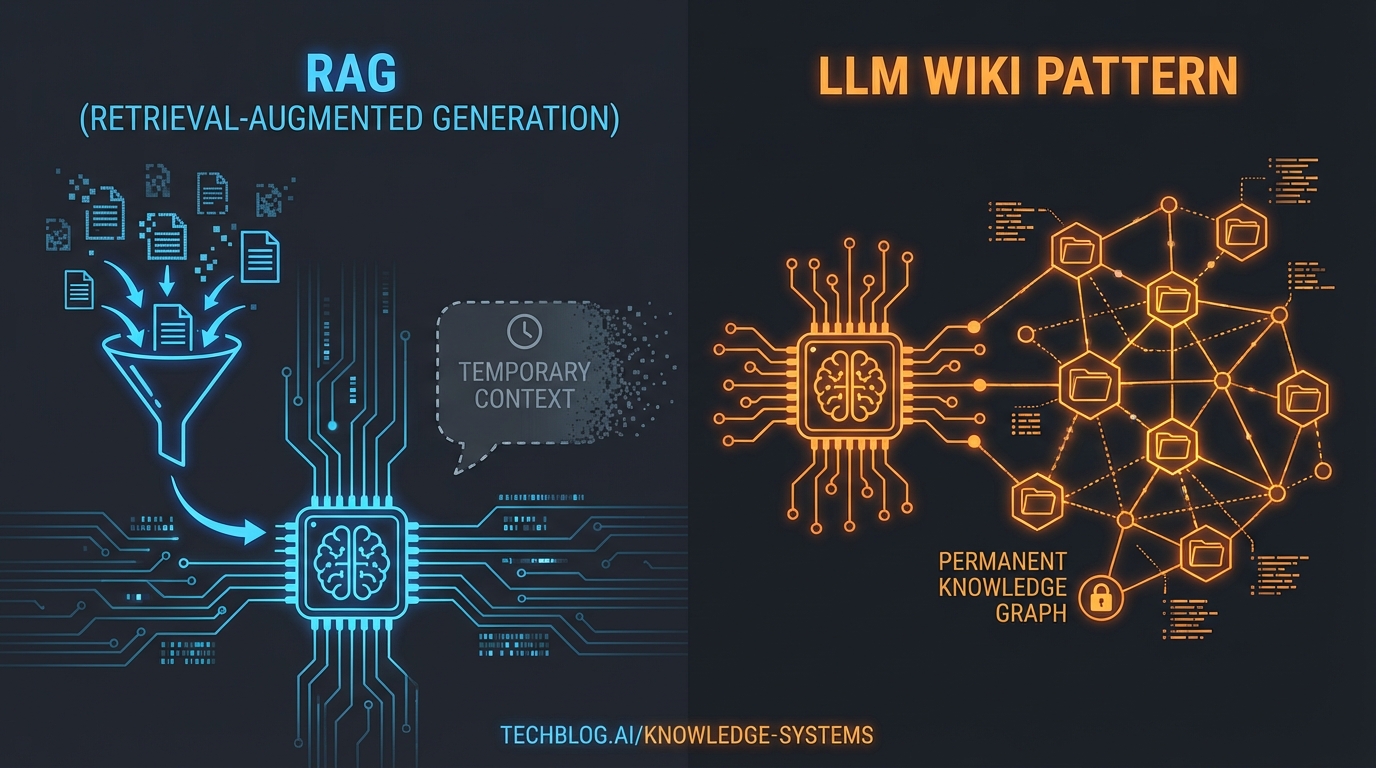
1. 传统 RAG 的核心痛点:缺乏“知识的复利”
目前主流的 AI 知识问答(如 NotebookLM 或各类 RAG 系统)的运行逻辑是:用户上传原始文档 ——> 提问 ——> AI 临时检索相关片段并拼凑出答案。
这种模式看似高效,但存在一个致命缺陷:系统是无状态的,知识没有积累。 每次你提出一个需要跨文档综合分析的问题,大模型都要像一个失忆症患者一样,从头开始搜索、阅读和拼接碎片。在这个过程中,没有任何结构化的知识被真正沉淀下来。
2. LLM Wiki 范式:AI 从“检索员”升级为“图书管理员”
Karpathy 提出的 LLM Wiki 模式打破了这一困境。其核心思想是:不再让 LLM 在查询时临时检索原始文档,而是让 LLM 持续构建并维护一个持久的、结构化的 Markdown 知识库(Wiki)。
在这个模式下,系统被明确划分为三个独立层级:
- 原始数据层 (Raw Sources):你收集的原始文章、论文、播客笔记等。这一层是只读的。
- Wiki 知识层 (The Wiki):由 LLM 完全接管并生成的 Markdown 文件目录,包含概念总结、实体页面、观点对比和深度综合。
- 架构规范层 (The Schema):一份指令文件(如
CLAUDE.md),告诉 LLM 应该遵循什么样的目录结构、双向链接规范和内容更新流。
3. LLM Wiki 的核心运作流 (Operations)
这套系统的运转完全颠覆了我们记录笔记的习惯,它包含三个极其硬核的生命周期:
A. 注入与内化 (Ingest) 当你扔给系统一篇新文章时,LLM 做的不再是简单的索引提取。它会仔细阅读文章,提取核心信息,然后主动去更新你现有的 Wiki —— 它会修改相关实体的背景介绍、更新主题的摘要、标注新数据与旧数据的矛盾点,并自动添加双向链接(Cross-references)。每一次注入,你的知识库都在进化。
B. 查询与反哺 (Query) 当你向知识库提问时,LLM 会基于已经结构化好的 Wiki 页面生成答案。更关键的是,那些产生出高价值分析、独特对比视角的优秀答案,会被直接作为新页面反哺(File back)进 Wiki 中。你的每次思考,都在让这套系统变得更厚重。
C. 系统体检 (Lint) 你可以定期让 LLM 给整个知识库做体检(Health-check),让它找出:自相矛盾的页面、被新信息取代的过时断言、没有双链的孤岛页面,甚至指示它主动通过网络搜索去填补数据空白。
4. 给我们的硬核启发:重塑分工
维护个人知识库最大的阻力从来不是“思考”或“阅读”,而是极其枯燥的“簿记(Bookkeeping)”工作:更新双向链接、梳理过时标签、同步多篇笔记的矛盾点。这正是过去大多数人放弃使用复杂 Obsidian 架构的原因。
但在 LLM Wiki 范式中,分工被极其优雅地重塑了: 人类负责策展信源、主导探索和提出好问题;而 LLM 负责包揽所有枯燥的整理、关联和维护等苦力活。
在你的工作流中,Obsidian 是集成开发环境(IDE),LLM 是永不疲倦的程序员,而这套知识库,就是你的底层核心代码(Codebase)。这不仅是个人知识管理的未来,更是我们在大模型时代建立终身竞争壁垒的最佳实践。