本周有两篇关于扩散语言模型(DLM)的重磅论文同时上线,巧合地指向了同一个方向——连续空间中的语言生成,而且都展示了非常漂亮的结果。
- ELF(Embedded Language Flows)来自 MIT 何恺明团队
- Cola DLM(Continuous Latent DLM)来自字节跳动 Seed 团队
它们试图回答同一个问题:语言生成一定要逐 token 自回归吗?
背景:为什么不是 AR?
自回归(AR)模型的推理有一个根本性的瓶颈:每个 token 的生成依赖前一个 token 的结果,导致延迟随输出长度线性增长,KV-cache 消耗随序列长度平方增长。且推理时 GPU 计算单元利用率很低(大部分时间在从 HBM 搬运 KV-cache 而非做矩阵乘)。
扩散模型在图像领域已经证明,非自回归生成可以做到质量更高、采样步数更少。把同样的思路搬到语言上,就是 DLM(Diffusion Language Model)。但之前的主流 DLM 都是离散 DLM(对 token ID 做扩散),性能和 AR 之间还有差距。
这两篇论文共同证明了一个关键结论:连续 DLM 可以做到比离散 DLM 更好,甚至接近 AR 的质量。
ELF:在 embedding 空间做流匹配
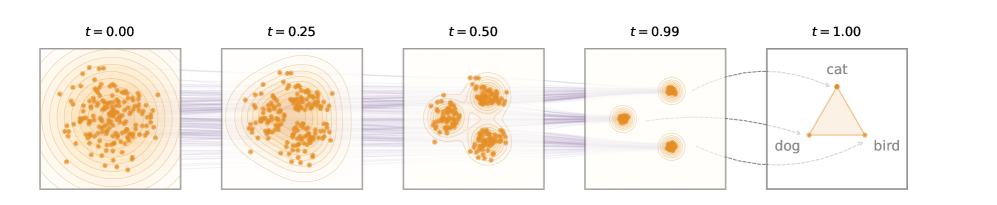 图:ELF 的概念架构。橙色点表示连续 embedding 空间中的数据,紫色线表示从 Gaussian 噪声到干净 embedding 的去噪轨迹。
图:ELF 的概念架构。橙色点表示连续 embedding 空间中的数据,紫色线表示从 Gaussian 噪声到干净 embedding 的去噪轨迹。
ELF 的核心思路非常直接:把文本生成看作在 embedding 空间中的连续路径。它基于 Flow Matching 框架,在连续 embedding 空间里做 diffusion,只在最后一步用一个共享权重的 decoder 把 embedding 映射回离散 token。
关键设计选择:
- Continuous embedding space — diffusion 在 embedding 层所在的连续空间中运行,不需要专门处理离散 token
- Shared-weight decoder — 同一个网络既做去噪(预测 embedding)又在最后一步解码(embedding → logits),参数共享
- Classifier-free guidance(CFG) — 从图像 diffusion 直接搬过来就能用,不需要修改
- 更少的采样步数 — 以更少的 ODE 步数实现了比离散 DLM 更好的生成质量
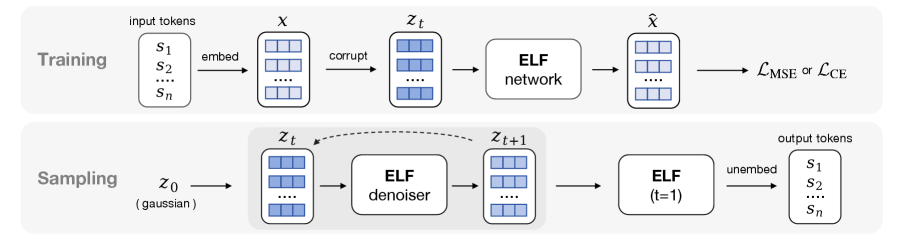 图:ELF 的训练 pipeline。干净 embedding 被添加噪声后,模型预测原始 embedding,decoder 再将其映射为 token 概率。
图:ELF 的训练 pipeline。干净 embedding 被添加噪声后,模型预测原始 embedding,decoder 再将其映射为 token 概率。
ELF 在 105M 参数规模上,用 10× 更少的训练 token 就超越了之前所有的离散和连续 DLM。
ELF 的特点:优雅、简洁、对图像 diffusion 技术的直接迁移。但只在小模型上验证,scaling behavior 尚未验证。
Cola DLM:三级架构的分层隐空间语言模型
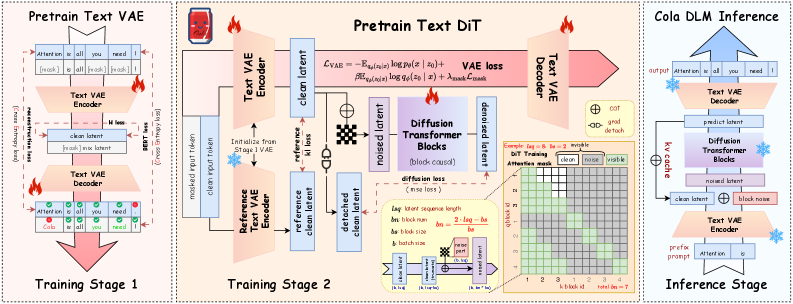 图:Cola DLM 的整体架构。三阶段 pipeline:Text VAE 压缩文本 → 隐空间 DiT 去噪 → 条件解码生成。
图:Cola DLM 的整体架构。三阶段 pipeline:Text VAE 压缩文本 → 隐空间 DiT 去噪 → 条件解码生成。
Cola DLM 走了一条更复杂的路线:三级分层架构。
它包含三个独立训练的阶段:
- Text VAE(文本变分自编码器)— 学习文本到隐空间的稳定映射。Encoder 把文本压缩为连续隐向量,Decoder 再把隐向量还原为文本。
- Block-causal DiT(块因果扩散 Transformer)— 在压缩后的隐空间中建模全局语义先验。DiT 完成去噪后,输出的干净隐向量包含了整段文本的”内容计划”。
- Conditional decoder — 基于去噪后的隐向量,并行生成所有 token。
这个过程的关键洞察:把”说什么”(全局语义规划)和”怎么说”(局部 token 实现)分开了。
- Diffusion 过程做的是隐空间先验传输(latent prior transport),而不是 token 级别的噪声恢复
- 这使得非自回归的归纳偏置更加灵活
- 自然支持多模态扩展(同样的架构可以处理图像、视频)
Cola DLM 在约 2B 参数规模上,与同规模 AR 和 LLaDA 基线做了严格对比,验证了 scaling 曲线到约 2000 EFLOPs——这是连续 DLM 领域目前最具体的 scaling 证据。
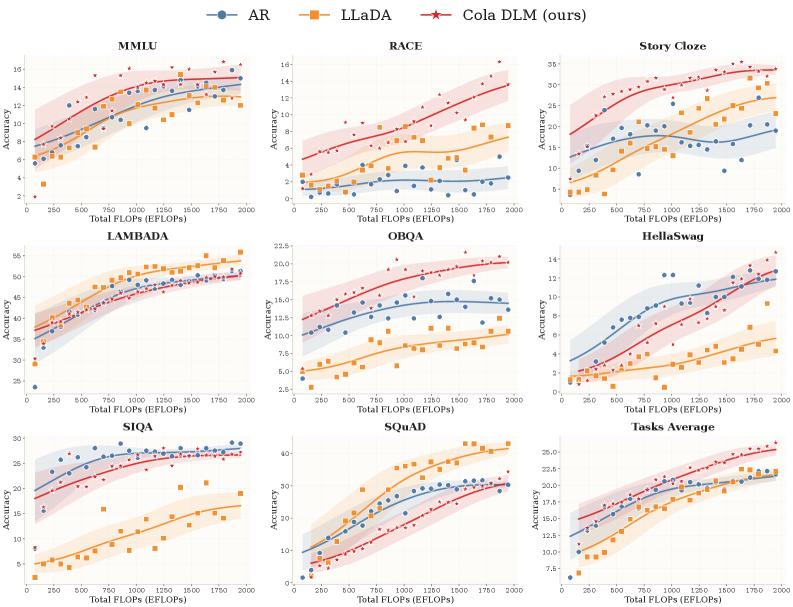 图:Cola DLM 的 scaling 曲线。在 8 个 benchmark 上的 Task Average 显示,连续隐空间 DLM 展现出与 AR 方法相当甚至更优的 scaling 趋势。
图:Cola DLM 的 scaling 曲线。在 8 个 benchmark 上的 Task Average 显示,连续隐空间 DLM 展现出与 AR 方法相当甚至更优的 scaling 趋势。
Cola DLM 的特点:架构更复杂,但有生产级的 scaling 证据。字节跳动正在规模化推进。
对 AI 基础设施意味着什么?
如果连续 DLM 从论文走向生产部署,它会改变 AI 推理的算力需求结构:
当前 AR 推理栈 → 未来 DLM 推理栈:
| 维度 | AR | 连续 DLM | 对硬件的影响 |
|---|---|---|---|
| 推理方式 | 逐 token 串行 | 隐空间并行解码 | 延迟更低(长文本),首 token 时延更高(去噪循环) |
| KV-cache | 与序列长度成正比,占 HBM 大头 | 隐空间瓶颈,KV-cache 很小 | HBM 压力减轻,CXL/eSSD 用于 KV-cache 可能没那么关键 |
| 计算瓶颈 | 显存带宽受限(反复读取 KV-cache) | 算力受限(DiT 去噪、ODE 求解器) | 瓶颈从显存带宽转向计算,更适合密集算力单元 |
| 批处理 | 难以跨时间步并行 | 天然可批处理 | GPU 利用率更高 |
| 能耗 | 显存搬运远多于计算 | 计算远多于显存搬运 | 每 token 能耗可能更低 |
关键结论:如果连续 DLM 成为主流,整个推理硬件设计方向会发生变化:
- KV-cache 优化的硬件(Astera 的重定时器、CXL 内存池、大容量 eSSD KV-cache 存储)的重要性下降
- 算力密集型的推理芯片(DiT 的 block-causal attention 需要大量 FLOPs)的需求上升
- 并行解码硬件(Groq 的 LPU、Cerebras 的 WSE)受益 — 它们原本就是为并行设计而非串行 AR 优化
- memory hierarchy 的焦点转移 — 瓶颈从”KV-cache 能装多少”变成”latent space 的表示质量”
两条路径的投资视角
ELF 路线(MIT): 更优雅的学术方案,小模型上表现优异。如果验证了在大规模上也成立,它的简洁性意味着更低的推理部署成本(简单架构 = 更少的硬件特殊化需求)。但还需要看到 scaling 到 7B+ 的结果。
Cola DLM 路线(字节跳动): 架构复杂、验证充分、scaling 数据具体。字节跳动已经证明了它在 2000 EFLOPs 上的有效 scaling。这是最可能率先走向产品化的路线。 如果字节跳动将其部署到豆包等产品中,将直接验证非 AR 推理在生产场景中的成本和效率优势。
对于关注 AI 基础设施建设的人来说——留意这两篇论文中提到的 scaling 数据和推理效率分析。它们可能是推理架构范式转变的前奏。
“Continuous DLMs can be made effective with minimal adaptation to the discrete domain.” — ELF 论文
“Generation quality and scaling behavior may better reflect model capability than likelihood.” — Cola DLM 论文
论文链接:
- ELF: arXiv 2605.10938
- Cola DLM: arXiv 2605.06548
项目页:
- Cola DLM: https://hongcanguo.github.io/Cola-DLM/
— Youmoo(㕛木)
Solid as teak. ⚡