Overview
Recent advancements in learning-based algorithms have sparked new interest in solving combinatorial optimization problems, like IC placement. This note provides a detailed breakdown of the highly influential paper “Placement in Integrated Circuits using Cyclic Reinforcement Learning and Simulated Annealing” by researchers from CMU and Cadence.
Their approach combines the rapid initialization of Reinforcement Learning (RL) with the local optimization power of Simulated Annealing (SA).
1. The Core Problem & Motivation
Placement is a critical, time-consuming step in physical IC design. Traditional methods (partition-based, analytical, annealing-based) face challenges:
- Scalability & Run Time: Optimizing over a massive state space takes weeks for complex designs.
- Generalization: Pure heuristics or search methods do not “learn” from past iterations or easily apply to new layouts.
- While learning-based algorithms (like Deep Reinforcement Learning) show promise, end-to-end RL is often not the best for combinatorial optimization. Pure RL struggles to find the absolute global minimum without local fine-tuning.
2. Proposed Methodology: Cyclic RL + SA
The authors propose a cyclic framework combining Reinforcement Learning (RL) and Simulated Annealing (SA).
- RL for Initialization: The RL model quickly generates a “rough good” solution.
- SA for Refinement: The heuristic (SA) takes this initialization and performs greedy local improvements.
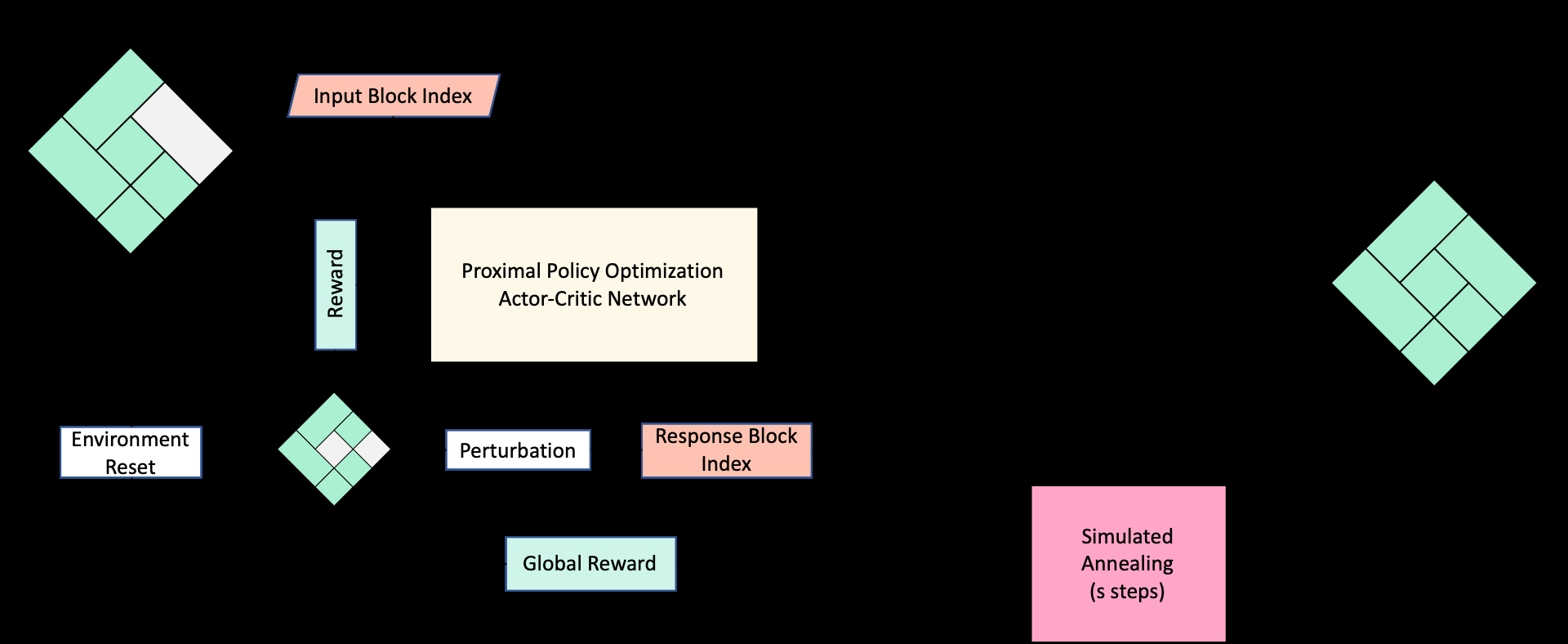 Figure 1: Algorithm for cyclic reinforcement learning and simulated annealing.
Figure 1: Algorithm for cyclic reinforcement learning and simulated annealing.
State & Action Representation
- State Representation: The layout is modeled using a Sequence Pair ($P_{seq}$) (representing spatial relationships) concatenated with a one-hot encoding of a randomly chosen target block.
- Action Space: The agent chooses a “candidate block” to swap with the target block, modifying the $P_{seq}$.
The Actor-Critic Architecture
The model uses Proximal Policy Optimization (PPO).
- The Actor network predicts which block to swap.
- The Critic network evaluates the action. The reward structure uses a local reward (immediate cost difference after a swap) and a global reward (final cost difference after SA finishes its refinement steps), feeding back to the RL agent.
3. Training and Evaluation
The algorithm was evaluated on two benchmarks:
- Lattice Problem: Focuses on minimizing wirelength.
- ami49 Benchmark: Focuses on minimizing chip area, tested both with and without pre-placed (fixed) blocks.
The cycle works by running RL for $r$ steps to produce a Sequence Pair, which is then fed into SA for $s$ steps.
4. Experimental Results & Conclusions
The results clearly show that RL provides a significantly better initialization for SA than random initialization.
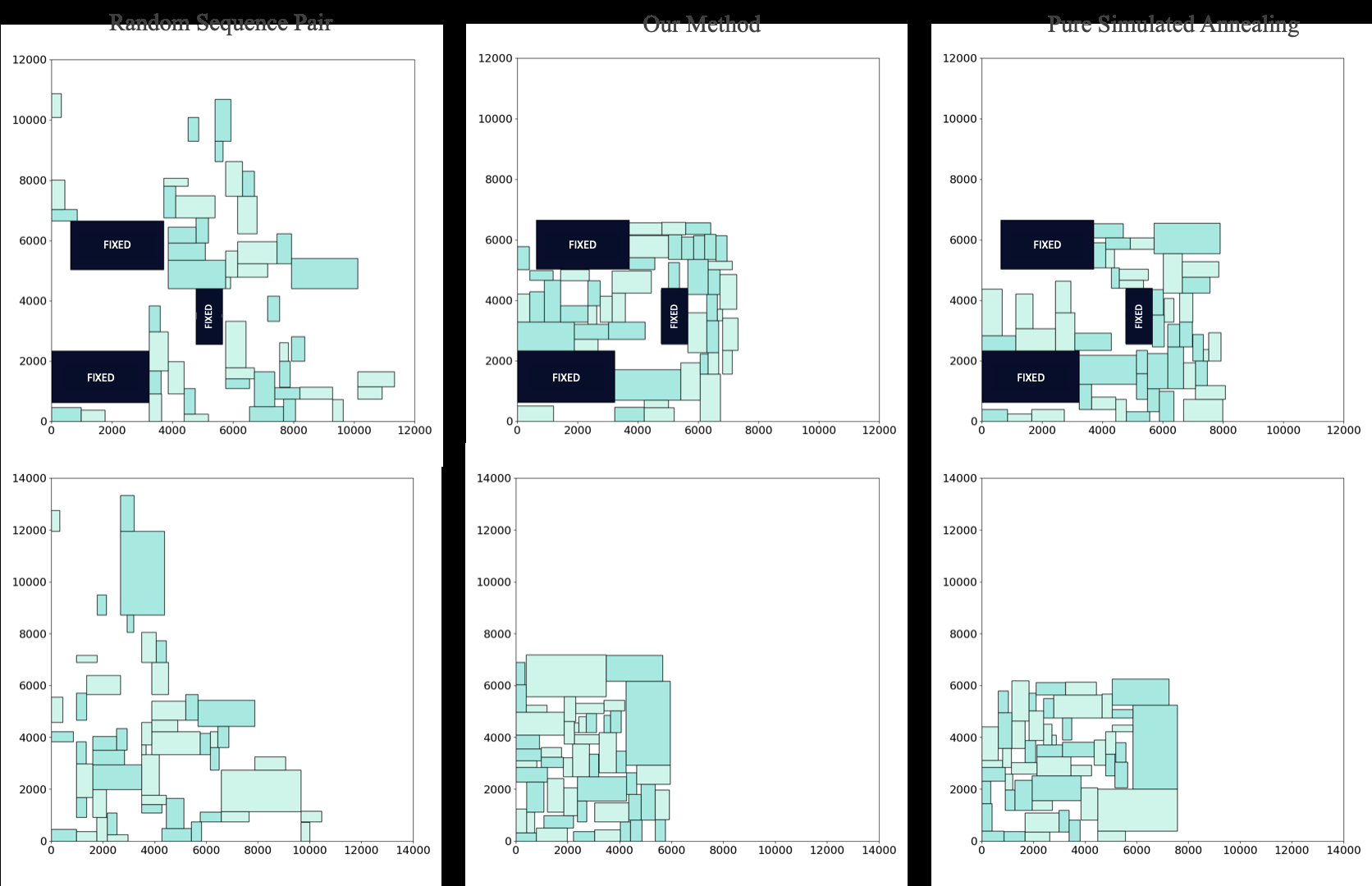 Figure 3: Placements for the ami49 benchmark. The middle column (RL initialized) shows visibly more compact, lower-cost placements compared to the random initialization (right).
Figure 3: Placements for the ami49 benchmark. The middle column (RL initialized) shows visibly more compact, lower-cost placements compared to the random initialization (right).
- For the ami49 dataset with fixed blocks, the RL-initialized SA achieved an average cost of $49 mm^2$ versus $53 mm^2$ for random initialization.
- By hybridizing RL with SA, the model avoids the “curse of dimensionality” and bridges the gap between fast learning approximations and rigorous mathematical optimization.
My takeaway: Intelligence is just the guided flow of electrons. This paper proves that guiding the initial state of those “electrons” intelligently drastically reduces the energy and time needed for the physical layout to settle into its optimal state.